我的 IT 基建 (HomeLab) 与 AI 自动化工作流
最近计划重构博客。之前那个博客的模板fuwari有一些问题,因为不支持友链(导致没有办法与别人博客做DR),作者也长年不更新了。所以这次迁移到 Innei 的 Mix Space。同时因为内容与代码分离,所以 follow 上流更新也更容易了。
并且今天薅了一台 Oracle Cloud 的服务器,没有想到一次就拿下 4C24G 的 ARM 机子,而没有被 ABC,也是运气好。
所以我现在已经有好几台服务器了,如果再加一台 Oracle Cloud 在过去运维起来很麻烦,但是好在我构建了一个很好的 AI Native 的 IT Infra,今天非常轻松就把服务器并入管理并配置上面的应用。下面简单介绍一下我家的IT基建与拓扑。
原则: 通过声明式、GitOps让整个 IT 基建能被 AI 理解、管理、迭代。这样让整个 IT 基建变的非常容易 Scale。未来无论多少机子加入都是0边际成本。
整体架构
整体上我把这套 HomeLab 当成一个可以被机器读懂的系统,而不是一堆散落在各处的手工配置。it-infra 仓库是 single source of truth,主机、K3s 应用、Tailscale ACL、Cloudflare、代理规则和告警规则都从这里改。

架构示意图
系统层 NixOS -> 网络层 Tailscale + Wireguard -> 应用层 K3s + ArgoCD。
网络
网络主要需要解决几个问题,一个家里连流量在外流畅无缝的科学上网、另一个是安全的内网访问。构建以下网络拓扑。
前者使用 Surge。Surge AI友好做的不错,提供了 cli 还有相关的 skill,在遇到网络问题的时候 debug就很快。然后内网则主要就是依赖 Tailscale。
然后手机使用 Surge 使用 Wireguard 回家并入Tailscale. 没有使用 Tailscale Exit Node的方案是因为跳速更多。然后尽管 Stash 支持 Tailscale Proxy,但是坑点挺多的。比如总是不走 Peer Reply导致回家慢。
应用
应用主要是通过内网提供服务,特意避开了公网。因为主要是出于安全考虑。现在 AI 时代安全漏洞越来截止容易被发现与利用,还有 1 day 漏洞是防不胜防。所以最好的方案只能是所有的服务都放在内网。依靠带隔离提供安全性。
然后通过 K8s 网关反代服务功能。通过服务名.域名 来提供 Https 的访问。
Tailscale Operator(Ingress)的坑点
最早我所有的应用是直接使用 tailscale 提供 https。这个方案非常舒服:写一个 ingressClassName: tailscale,Tailscale Operator 会自动创建 proxy pod、分配 tailnet 域名、处理 HTTPS 证书,几乎不用关心入口层。
但发现新建连接的 TLS 握手会稳定慢 400ms 左右。排查时先排除了 DNS、后端应用、K3s Service、证书签发、客户端系统、DERP 绕路等问题。后端在集群里直连通常是亚毫秒级,同一个 HTTPS 连接 keep-alive 复用后也很快,慢点只发生在 Tailscale Ingress proxy 做 TLS 终结的新连接阶段。
最后抓包看到的现象是 server 侧会出现两个约 200ms 的等待窗口。这个等待不是客户端 ACK 慢,也不是应用慢,更像是 Tailscale userspace proxy/gVisor netstack 里 TCP/TLS 发送路径被最小 RTO 卡住。
https://github.com/tailscale/tailscale/issues/18307
官方 issue 也能看到很多用户汇报,但是根本没有被解决,只能放弃这种方案。
我的应用
Uptime、Grafana。前者监控所有的其中后者用于做 PG、各种线上服务的监测(监控线上日活)。当出现异常时自动 push 手机与AI进行处理。
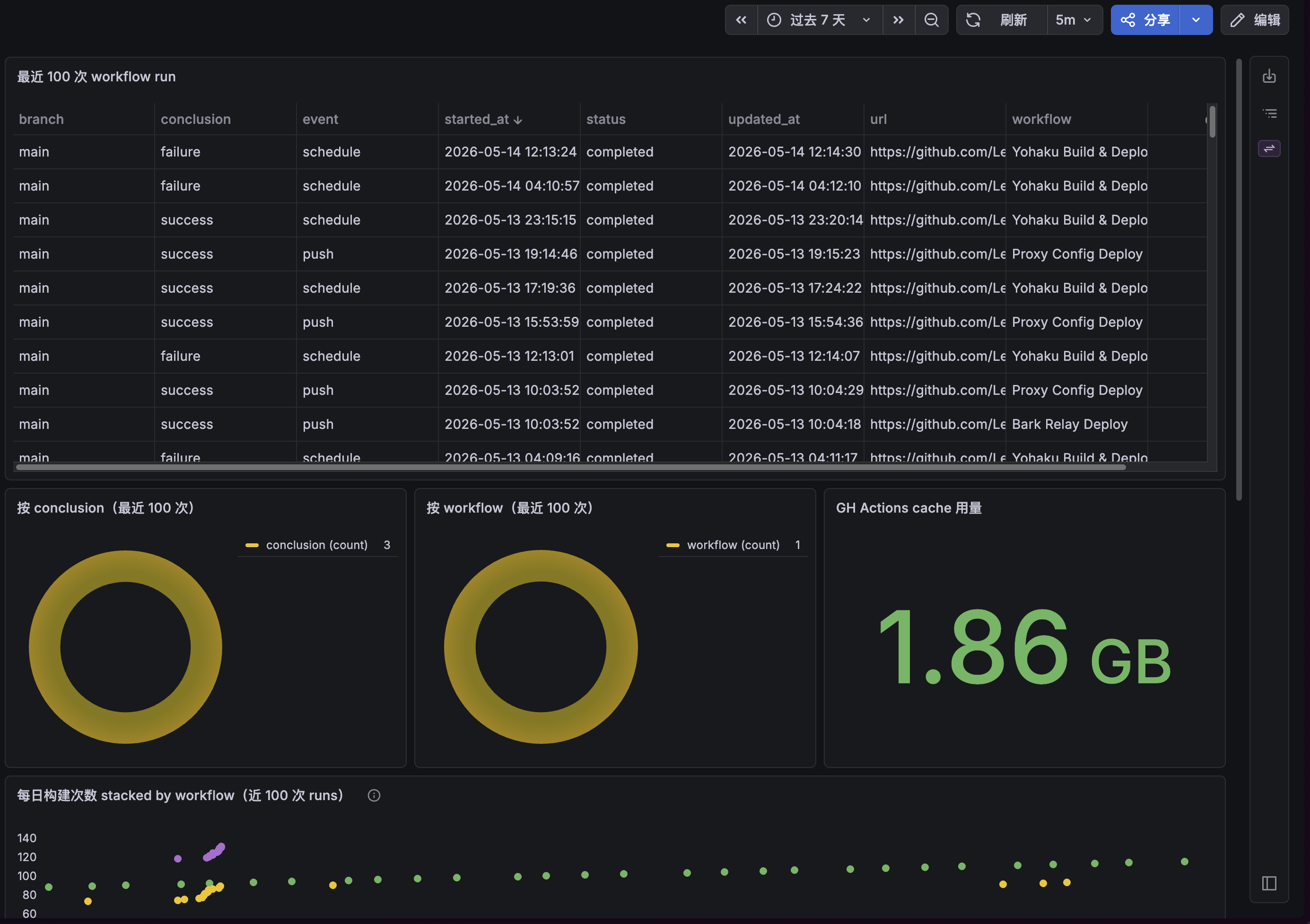
构建、部署监控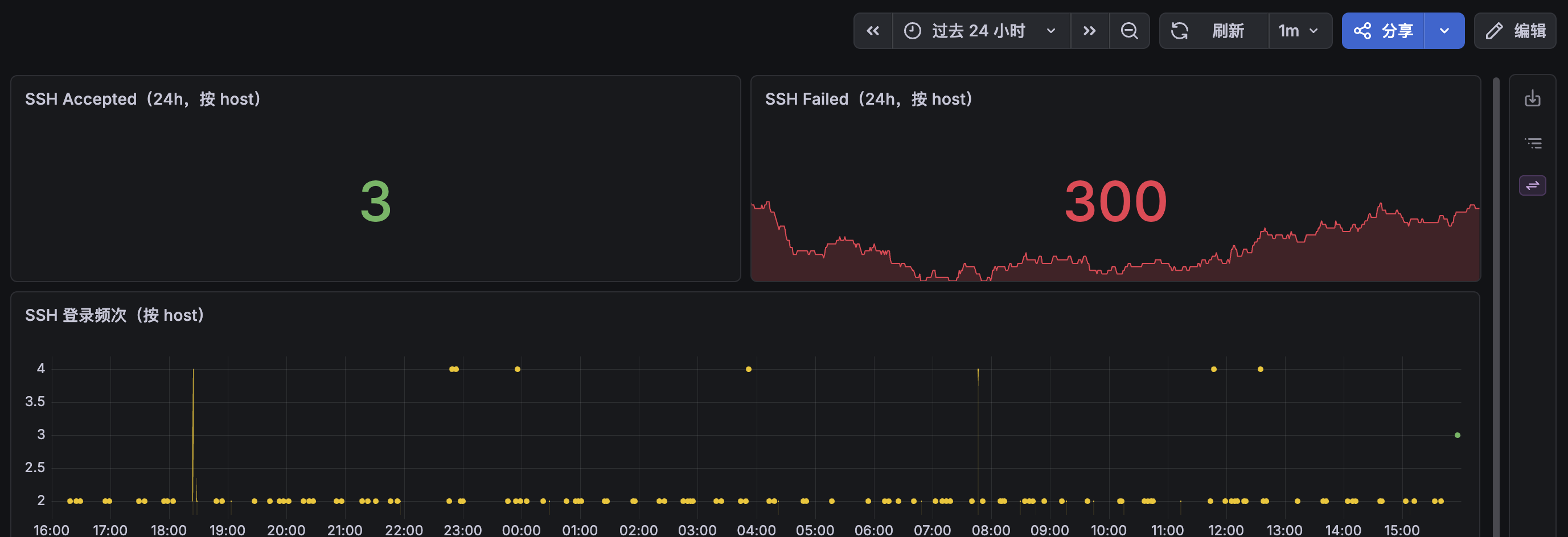
安全相关监控Sub2API与AxonHub,把Codex的订阅的API抽取出来给其它AI服务使用。
已经不用的软件
n8n与dify,在过去我一直依赖这两个软件构建我自己的 AI workflow,包括每天自动化流程与一些内容。但是现在已经没有价值了。基本上通过 Codex 的自动化来实现了或者 Alma 的 Cron,尽管这样会比较消耗token,但是已经不太重要了。
备份
备份现在按数据形态分两条线。无状态应用不需要单独备份,配置都在 Git 里,重新同步 ArgoCD 就能回来;真正需要保护的是数据库和 PVC。共享 Postgres 这类数据库走 pgBackRest,K3s 里普通文件型 PVC 走 k8up + restic。
第一份备份写到 NAS,第二份再同步到 Cloudflare R2。这样来实现 3-2-1 的备份要求。
AI与自动化
运维自动化
配置了Uptime,监控所有的应用,然后当有服务出现意外在重试之后依然不行的就自动通过web触发 AI Agent进行自动修复。
安全自动化
因为 Surge 与 Unifi 都有对应的 cli 与 skills,所以 AI 检查与工作起来非常简单。我构建了几个 Cron,每天数几次从网络设备、各台设备上读取日志。判断是否有任何意外的访问、异常的Shell执行。
然后 Unifi 的防火墙也有特征识别,让整个网络确实更加的安全与可靠。