前情
TechStack 是一个用于显示一个 GitHub 项目的技术栈的浏览器插件。在开发它的过程中,我遇到一个挺有意思的技术需求。
比如在 package.json 中,我们可以通过依赖项 react 直接映射到 React 技术栈。但是有些依赖并不是这样。 比如 @radix-ui/react-checkbox 和 @radix-ui/react-icons 它们都属于 Radix UI 的一部分,如果让这些依赖直接对应到 Radix 呢?
我觉得大部分人都很想容易想到正则。对,可以写一个正则,大概是这样@radix-ui/[\w-]+,如果被它匹配到就是 Radix。
所以我就想搞一个数据结构,一个 key 可以是 string 也可以是正则的map。🤔 就像这样
CodeBlock Loading...
开工!
实现第一版
先大概验证一下想法的可行性,我直接干了一个map,大概像这样
CodeBlock Loading...
当我们去取一个值时,遍历所有的正则表达式。可以看到这个实现的时间复杂度为 O(n),n 为正则表达式的数量。这个复杂度其实在我的业务中是可以接受的,因为正则表达式的数量不会太多。🤔但是都要做成库的话,肯定不能止步于此。
benchmark
先来做个benchmark,不然怎么能知道后面提升多少呢!
CodeBlock Loading...
这里看起来数据量小的时候还凑合,直接上大数据量
CodeBlock Loading...
大概测了一下,可以看到当数据量达到10000时,就慢的可怜。😭
实现第二版
🤔我当然不能满足这么差的性能表现呀! 怎么做呢? 凭我的直觉,我感觉可能用一个二分再搭一个树就能把时间复杂度优化到Log(N),感觉这个性能是可以勉强接受的。
直接开工,大概代码如下
CodeBlock Loading...
benchmark
CodeBlock Loading...
🤔可以看到其实性能不增反降,这很反直觉,不应该是这样。直接上 pprof,看看问题在哪里。
通过pprof,我定位到时间大概花了 Regexp Compile 和 GC 上,后者先不管,先看看前者。我们现在的 regexp 是在 Store 时生成的,所以明显会有多次不必要浪费的 Compile,所以这个可以lazy一下,当用到时再 Compile。
我原来的代码大概是 Insert 时 compile 正则,现在是 Find 时 compile 正则
因为原来Insert之后可能还会有Insert,会让原来的编译出来正则用不上,所以这个编译其实是无用的。
Lazy compile
在把代码改了一下之后,就OK了。可以看到性能提升了很多。
CodeBlock Loading...
其它优化
然后就是在树上继续修修改改,看看能不能把GC时间也减掉一点(就是少用指针)🤔。
如何保持树的平衡
平衡树,大家很容易想到红黑树。但是其实红黑树并不适合我们,因为红黑树会改变节点的顺序,而顺序会重建 regexp。所以我们目前是尽可能在插入时保证树的平衡。🤔
所以我想到一个很骚的平衡算法🤪 随机插入,通过随机性来保证树的平衡。🤣目前看来其实还能接受。
后续优化
其实二叉树并不是正则Map一个适合的树,完全可以上多叉树🤔所以后续的优化就是上多叉树。后续我研究一下 B 树,看看能不能把借鉴一下相关的思想。
安全性检查
可以看到这个Map是有一个要求的,也就是每个正则表达式都要能匹配到一个唯一的值。所以我们需要一个安全性检查,来保证这个要求。
这个实现也很简单,就是判断是不是左右能匹配的上,如果左右子树都匹配的上就是出问题了。
但是这个目前没有一个好的表现方式,我打算额外做一个函数,比如 安全的Load。在这里取值时额外检查,如果遇到问题就是 panic。
线程安全
这个是还没有做的,目前还是用普通的 Map,后续考虑用 sync.Map 加一些其它机制来实现线程安全。
总结
从一个需求到落地代码,大概用了一个晚上+一个中午。还挺兴奋的,特别是每次跑通测试,或者一个 benchmark 相较之前有所提升的时候。🤣 还是挺有成就感的。
其它
目前这个 Regexp Map 已经在 GitHub 上了,可以在这里找到文档和代码 : https://github.com/CorrectRoadH/regexp_map
然后就是运营时间😗 TechStack 是一个用于显示一个 GitHub 项目的技术栈的浏览器插件。可以快速判断一个Github项目的技术栈,一眼判断出是不是假开源项目。目前已正式结束测试,欢迎大家来试试。
Chrome: https://chrome.google.com/webstore/detail/tech-stack-show-github-re/lbhjnhabgddabnagncmcgomggeadlbhh
Firefox: https://addons.mozilla.org/en-US/firefox/addon/tech-stack/
比如这个: FastGPT,虽然看到这个是一个前端项目,不过能看到有调 OpenAI 和用到 Postgres ,所以一眼就可以判断出应该是一个真的开源项目,也可以大概判断出实现思路,比如是用 Postgres 做向量数据库。
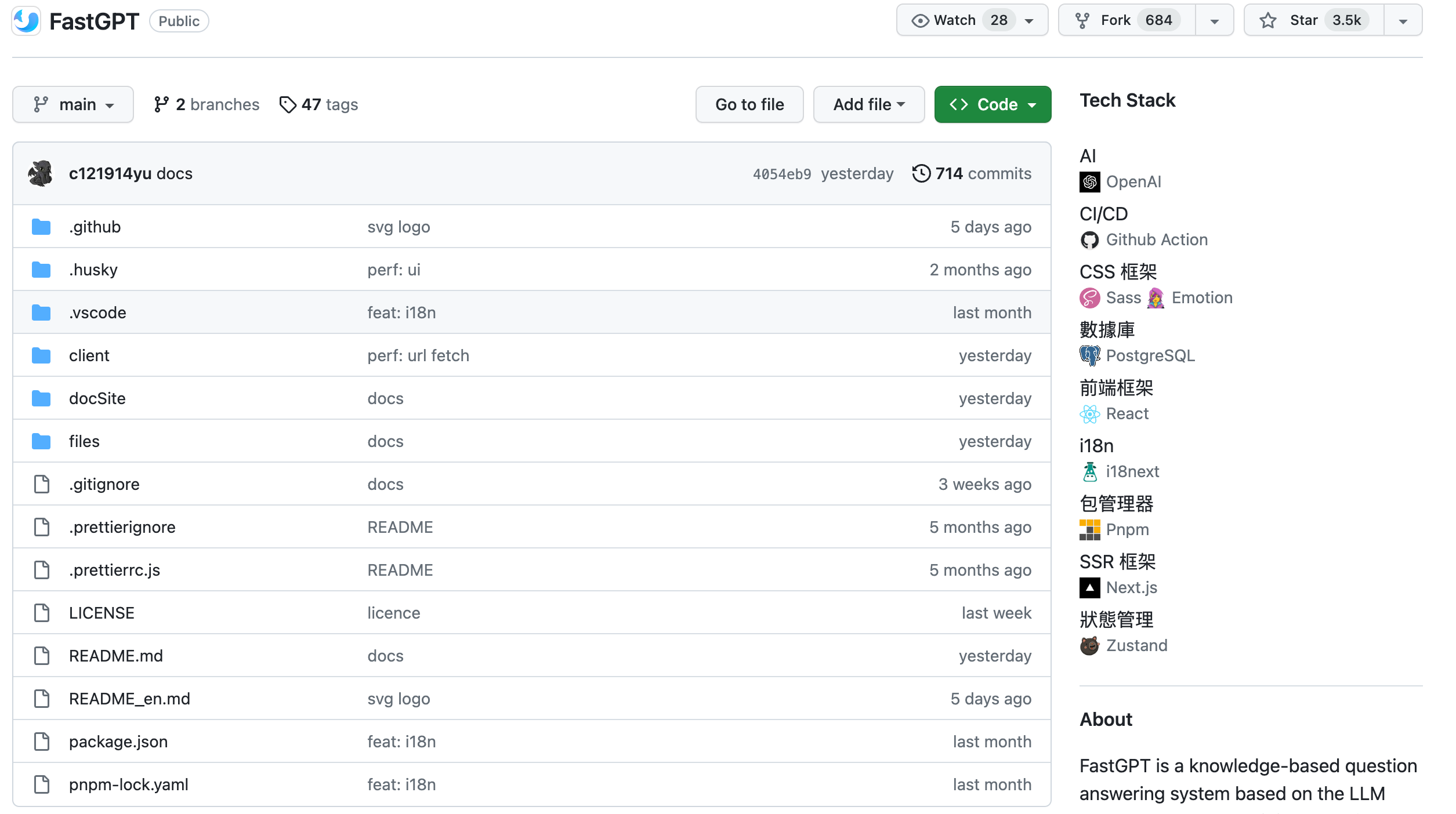
FastGPT GitHub 主页的截图